Su Usted busca por "noosfera" [ Nota 1 ] al día Martes 12 de Abril, a las 2:22 PM Tiempo del Este para Estados Unidos y el Canadá del presente año en el buscador Altavista, encontrará 30.136 páginas que tratan sobre ese concepto. Es ésta una extraña palabra que aún no merece una entrada en la versión en línea del Diccionario Merriam Webster. Sin embargo, conocemos y usamos el Ciberespacio, neologismo que tiene 777.290 entradas en el mismo Altavista, pero que por el contrario, tiene una entrada en el mencionado diccionario desde el año 1986, con el siguiente significado: el mundo en línea de las redes computacionales. Espacio Web es otro neologismo aún no incluido en ese diccionario pero que merece 485.805 entradas en Altavista.
El espacio Web crece a un ritmo fantástico atesorando hoy casi 500 millones de documentos, que van, desde Bibliotecas Virtuales de libros de referencia virtuales o e-libros que tratan los Temas Mayores del Conocimiento Humano, a efímeras novedades y avisos generados "sobre la marcha" como al azar y en forma continua. Dentro de ese espacio se pueden encontrar documentos pertenecientes a una de tres grandes categorías de Recursos Internet: Información, Conocimiento y Entretenimiento.

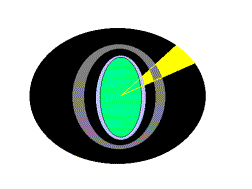
En la figura de arriba la corona negra representa el Espacio Web y el círculo verde a los usuarios. La corona gris representa una red intermedia, aún inexistente, a ser construida en un futuro cercano, con Resúmenes Inteligentes del Conocimiento Humano, que nos conducen a los documentos básicos de ese conocimiento. Se muestra un usuario extrayendo un "cono" de lo que necesita, pero en términos de resúmenes: de información y de conocimiento. Los resúmenes inteligentes deben servir como guías introductorias enriquecidas con vínculos hipertextuales y enlaces inteligentes. Si el usuario desea mayor detalle va entonces a buscar su e-libro a la región negra. Dependiendo del Tema Mayor tratado, el usuario puede navegar saltando de resumen en resumen o a guías de nivel superior, siempre dentro de la corona gris o ir a la zona negra para la búsqueda de temas específicos.
Se muestra a otro usuario yendo directamente a la región negra guiado por los motores de búsqueda clásicos, como hoy en día. La región negra, que crece exponencialmente en volumen será siempre necesaria. Por el contrario, la región gris tendrá un volumen fluctuando alrededor de valores medios de poco o nulo crecimiento. Efectivamente, el Conocimiento Humano es casi acotado en volumen, cambiando solo su contenido y su semántica. El crecimiento de la corona gris es extremadamente bajo en comparación del de la región negra. Excepcionalmente, algunos Temas mayores mueren y otros nacen pero muy lentamente.
Como ejercicio de ciencia-ficción se invita al lector a hacer algunos cálculos, al estilo de las historias de Isaac Asimov. Si acotamos el Conocimiento Humano a digamos 250 Temas Mayores o disciplinas y si para cada una de ellas definimos en promedio una Biblioteca Virtual de 2000 e-libros no redundantes, tendremos un volumen de 500,000 e-libros. Si ahora creamos una metodología para sintetizar resúmenes inteligentes de cada uno de ellos, de no más de 2.000 caracteres, totalizaríamos 1.000 MB ó 1GB, almacenando a razón de un carácter por byte. ¡Ese sería el volumen de la región gris!. ¡Bastante poco en realidad!.
Comparemos ese volumen con el de la región negra y con el que ocupan los recursos básicos del Conocimiento Humano. Considerando un Espacio Web de 500 millones de documentos con un volumen unitario promedio estimado en 2,5 MB: con documentos que van desde 10KB y menos a 100 MB y más. ¡Lo cual nos da un volumen de aproximadamente 1250, 000,000 MB!. Dentro de éste espacio gigantesco flota disperso el espacio de e-libros básicos, que ocuparía un volumen estimado en 500.000 MB, asignando 1MB a cada uno, medio millón de caracteres en texto y 100 imágenes de 5 KB cada una en promedio.
Región negra: ~1,250,000 GB => CH ~ 500 GB => Región Gris ~ 1 GB
Nota: Para llegar a 2,5 MB hemos supuesto la siguiente escala arbitraria de tamaños 1, 10, 100, 1.000, 10.000, 100.000 en KB y asignamos a ellos las siguientes escalas arbitrarias de peso: .64, .32, .16, .08, .004, .002 respectivamente.
Increíble resultado que demuestra cuán fácil es compilar una relativamente estable corona gris RICH, por Resumen Inteligente del Conocimiento Humano, o Mapa del Conocimiento Humano con relación a la inestable, ruidosa, efervescente y siempre creciente región negra. Una vez realizado el esfuerzo, su actualización sería facilitada por Sistemas Expertos que extraerían de la Región Negra solo los cambios.
El Espacio Web luce como el Cielo de noche
En la figura de arriba mostramos al actual Espacio Web en negro, similar al espacio del Universo físico. Sin duda, la información que como usuarios necesitamos está allí, pero ¿dónde?. Ese espacio virtual luce para nosotros como negro. Algunos miembros de ese espacio que suministran servicios de búsqueda, Motores de Búsquedas y/o Directorios Web, son como estrellas que irradian luz sobre el espacio para que podamos ver algunos cuerpos en forma indirecta, con la luz reflejada. Podemos también encontrar algunos cuerpos con luz propia, como las estrellas, activada por la publicidad en medios convencionales. El resto, la casi totalidad, es solo débilmente iluminada.
Para cada sitio ubicado en ese espacio en un URL, que significa Localizador Uniforme de Recursos, los robots de esos servicios de iluminación preparan un breve resumen con alguna información extraída de ellos, no más de un párrafo, el cual es almacenado en las bases de datos de esos servicios. Estos resúmenes incorporan algunas palabras claves extraída de los recursos visitados y son usadas para indexarlos. Es decir, un recurso es indexado en todas "sus supuestas" palabras clave.
Los robots actuales son muy "listos" pero extremadamente primitivos comparados a los seres humanos. Hacen sus tareas en fracciones de milisegundos por recurso y sería impracticable hacerlos mucho más listos pues el tiempo de evaluación crecería exponencialmente con el nivel de inteligencia. Para facilitar el trabajo de los robots los programadores y desarrolladores de Web tiene a mano sabias herramientas, que lamentablemente muchos sobre usan haciéndolas inservibles para su fin. En resumidas cuentas, mediante esas herramientas los programadores comunican a los robots la información esencial que los propietarios del sitio desean se conozca.
Estos puentes de inteligencia artificial se han convertido en ruidosos pues la mayor parte de los propietarios de los sitios tratan de engañar a los robots sobre vendiendo lo que sería su equidad básica. ¿Porqué lo hacen?. En parte obligados por las circunstancias. Los Motores de Búsqueda presentan a los sitios en forma jerárquica, ¡el primero supuestamente el mejor!. Ocurre algo similar a lo que ocurre con los Avisos Clasificados de los diarios: la gente que desea ser ubicada primero llega a hacer uso poco ético de la primera letra del alfabeto: AAAAAAA Servicios del Hogar, por ejemplo, va primero que AA Servicios del Hogar. Los Motores de Búsqueda no tienen demasiado espacio para crear un escenario justo que liste a los recursos con equidad.
Un criterio trivial podría ser contar cuántas veces una determinada palabra clave es citada dentro del recurso pero eso conduciría a errores porque los robots buscan en forma restringida, siendo prácticamente imposible para ellos diferenciar un sólido tratado académico de un trabajo práctico estudiantil acerca de un determinado tema. Aún más grave, los programadores, desarrolladores y expertos en contenido saben todos los trucos para engañar a los robots y en consecuencia, hacen mal uso de las palabras clave que consideran significativas para potenciales usuarios.
Los Motores de Búsqueda han mejorado mucho en los dos últimos años pero el proceso continúa siendo ineficiente y se tiende al colapso del sistema. Para arrojar más luz que permita a los propietarios de sitios acceder a mejores posiciones proliferan método y programas, éticos y no éticos, destinados a desorientar a los Motores de Búsqueda. No obstante, aún en una utopía de Buena Fe sería muy difícil para un robot diferenciar un sitio complejo y brillante de uno humilde y mediocre que traten del mismo tema. Incluso existen hoy arquitecturas complejas que son invisibles a dichos robots, preparados para evaluar estructuras "planas" y simples.
Enfatizamos nuevamente el hecho que la luz que suministran los Motores de Búsqueda a un URL es indirecta, como La Luna refleja la luz del Sol. De allí nuestra conclusión: la mayor parte de la información y el conocimiento está oculta en la oscuridad del Ciberespacio.
El Reino del Desencuentro
Ahora que sabemos el significado de CH. Conocimiento Humano, podemos definir los RICH, Resúmenes Inteligentes del Conocimiento Humano, un conjunto de resúmenes del que debemos explicar porque llamamos inteligente y la RRICH, por Red de Resúmenes Inteligentes del Conocimiento Humano, que se corresponde con la zona gris de las figuras de arriba. Vamos a entrar ahora en el problema de los lenguajes y jergas hablados en la Región Negra, en la Región Gris y fundamentalmente en la Región Verde.
Internet como Reino del Desencuentro
Los sitios Web son creados para el encuentro con sus usuarios, son como faros en la oscuridad, que irradian información y conocimiento y en el caso del Comercio Electrónico una clase de información que denominamos "oportunidades". Lo que ocurre hoy es que Internet es más un reino del desencuentro que del encuentro. Los dueños de los faros no pueden encontrar a sus usuarios potenciales y los usuarios no pueden encontrar las supuestas oportunidades ofrecidas ni entender los mensajes. Este escenario de desencuentro es dramático en el caso de los Portales, grandes faros creados justamente para atraer tanta gente como sea posible vía "atracciones" generales.
Algo similar ocurre con las bases de datos donde hay almacenados millones de registros con supuesta información útil, tal como catálogos, servicios, manufacturas, profesionales, oportunidades laborales, firmas comerciales, etc: Los usuarios no pueden encontrar lo que necesitan. Cuando decimos desencuentro nos estamos refiriendo a cifras superiores al 95% y en algunas bases de datos hemos medido encuentros inferiores al 0,1%.
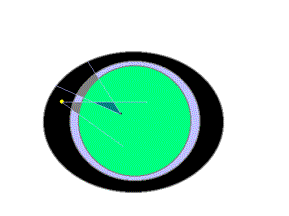
En la figura se muestra éste dramático desencuentro. El punto amarillo es un sitio Web con su oferta representada por el cono emergente, digamos la Oferta expresada en su lenguaje y en su jerga particular. Un punto negro dentro del círculo verde representa a un usuario y el cono emergente su Demanda, expresada también en su lenguaje y en su jerga particular.
Los Sitios Web y los usuarios hablan y piensan diferente
Ambos lados hablan una lengua parecida pero casi siempre una jerga diferente y aún más: ¡piensan diferente!. Mostramos la corona gris porque la porción correspondiente a su Tema Mayor (el de la figura) virtualmente existe: es la porción de gris oscuro dentro del cono para cada parte. El sitio dice tener la "verdad", expresada en su jerga particular, probablemente una jerga "oficial" y estándar. Si el sitio fuera por ejemplo, un "Vertical" de la Industria Química, su jerga sería la oficial de esa industria y su menú estaría expresado en forma técnicamente correcta, pareciéndose al Índice de un Manual para ese Tema Mayor particular: Industria Química.
Nuestra conclusión a lo largo de dos años estudiando las causas del desencuentro es que los faros hablan - o intentan hablar- jergas oficiales certificadas por el orden establecido de sus Temas Mayores particulares. Se supone que poseen la verdad y en cierto modo actúan como maestros del Ciberespacio. Sus verdades estarían representadas en sus menús, estructurados de hecho como "árboles lógicos". Estos sitios pretenden ser e-libros y se comportan, piensan y lucen como libros físicos.
Si el usuario accede al sitio para aprender, la convergencia de los conos es obligada, los usuarios piensan en términos de conceptos del menú, el cual para ellos luce como un Programa de Estudio y tenemos un escenario de encuentro. Si el usuario accede al sitio para buscar algo que necesita el asunto es diferente. Cuando alguien busca tiende a pensar en palabras clave, no en conceptos de un programa de estudio, palabras que pertenecen a su jerga propia y a la larga, a su Tesauro. Así se trate de un usuario experto o de uno que se inicia, los conos divergen significativamente del cono del sitio. Una de las razones de ésta divergencia es que los propietarios del sitio ignoran lo que su mercado necesita. Muchos de ellos están migrando de negocios convencionales hacia el Comercio Electrónico y erróneamente extrapolan experiencias. A lo largo de décadas llegaron al encuentro semántico de sus mercados y ahora se encuentran ante usuarios provenientes de todo el mundo cuyas jergas y comportamientos desconocen.
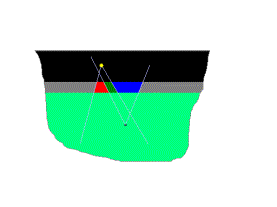
Evidentemente la solución será la evolución del desencuentro al encuentro del modo más eficiente. Para lograrlo, ambos, la Oferta y la Demanda, deberán aproximarse hasta lograr un escenario gana-gana y una jerga común.
En la figura de arriba mostramos una condición de desencuentro donde distinguimos tres zonas: la zona roja que representa el conocimiento que no se usa; la zona verde oscura, que corresponde a una sección común, con la concordancia de un Tesauro común; y la zona azul que corresponde a lo que los usuarios, necesitan, buscan, pero que aparentemente no existe dentro del sitio. Los propietarios del sitio tienen a su alcance dos líneas de acción: a) reducir a cero las zonas rojas, por ejemplo, adaptando y/o modificando supuestas "atracciones" y b) aprender tanto como sea posible sobre la zona azul.
En éste momento las zonas verde oscuras son extremadamente pequeñas, menos del 5%, siendo Internet el Reino del Desencuentro entre las Demandas de los Usuarios y la Oferta de los Sitios. El gran esfuerzo a ser realizado consiste en minimizar costos eliminando atracciones no usadas y aprender de las necesidades insatisfechas. Para el logro de ambos propósitos los propietarios de los sitios necesitan herramientas inteligentes, agentes que avisen de eventos en zonas azul y roja en forma diferenciada.
Vamos a analizar el proceso básico de la interacción entre usuarios y sitios. El usuario interactúa en dos formas: haciendo clic sobre un vínculo o llenando un formulario o caja con algún texto, por ejemplo, haciendo una consulta a una base de datos. Las estadísticas del sitio están preparadas para contabilizar los clic, diciendo además qué "caminos" del sitio fueron recorridos por cada usuario pero no suelen estar preparadas para contabilizar las interacciones derivadas de lo textual. Lógicamente se pueden registrar las consultas e incluso las respuestas pero eso no es suficiente para aprender del desencuentro. Para ello, debemos crear agentes inteligentes que contabilicen los componentes de cada respuesta, por ejemplo, documentos, pero ello obligaría a un pesado proceso de cómputo.
Si por ejemplo consultamos a una base de datos comerciales del tipo "Páginas Amarillas" por "neumáticos", la respuesta podría ser un listado de negocios que los proveen por zona geográfica; y para tener estadísticas acerca de la frecuencia con que los usuarios consultan esa palabra clave especifica debemos contabilizarlo; y para saber acerca de la "presencia" de cada negocio necesitamos ir un paso adelante contabilizándolo y así siguiendo. Este proceso involucra una enorme carga del servidor.
Un enfoque inteligente sería tener todos los contadores posibles dentro de los datos a ser consultados. Este es parte de la idea: proveer a cada resumen de un conjunto de contadores, uno para cada tipo de estadística necesaria. De ésta manera, cuando un dato es requerido se activan contadores que contabilizan: la "presencia" de un resumen; cuando es "seleccionado" por un clic y; cuando el usuario hace clic para acceder al e-libro o cuando hace clic para "salir" del sitio hacia un vínculo existente en el resumen.
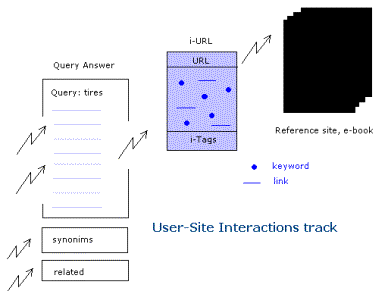
Arriba se representa una típica secuencia de interacción usuario - sitio. El usuario consulta "neumáticos" (tires). La i-Database, Base de Datos de i-URLs o de URLs inteligentes responde enviando todos los documentos indexados por neumáticos, agregando una lista de sinónimos y palabras clave relacionadas. Cada i-URL activado contabiliza su presencia en una consulta sumando un uno a su contador correspondiente en su zona de i-Tags o de Rótulos inteligentes. Si el usuario hace clic sobre un i-URL específico, el sistema contabiliza ésta decisión en otro contador interno
Finalmente, si el usuario decide acceder al sitio comentado, ubicado en la Zona Negra haciendo un clic, se activa otro contador diferente. Al mismo tiempo, el contador correspondiente a la palabra clave neumáticos es activado sumándosele un uno y lo mismo sobre los contadores de sinónimos o palabras clave relacionadas. Si la respuesta es cero ello significa un desencuentro, causado por un error o una señal de artículo inexistente en la base de datos. En ambos casos el sistema tiene que activar contadores diferentes para el error o para el caso de inexistencia en la base de datos a fin de contabilizar la popularidad de cada desencuentro específico. Si la popularidad es alta, es una señal acerca de la conveniencia de aceptar la palabra clave no encontrada como sinónimo o como palabra relacionada. Simultáneamente el sistema puede urgir a buscar información dentro de la Región Negra. De tiempo en tiempo el sistema puede sugerir la revisión de los resúmenes almacenados en la base de datos de los i-URLs, URLs inteligentes o también para asignar documentos a nuevas palabras clave.
Dentro de la característica de inteligente consideramos el registro del IP de las interacciones y las secuencia semántica de las consultas asociadas en particular a los desencuentros. Las cadenas de palabras clave están relacionadas a subtemas específicos dentro del Tema Mayor del sitio. Así, estadísticamente, el análisis de esas cadenas nos habla de la popularidad de los subtemas del menú, sugiriendo reestructuraciones del árbol lógico inicial.
[1] La noosfera es la parte del mundo vivo que es creada por el pensamiento y la cultura del hombre. Pierre Teillhard De Chardin, Vladimir Ivanovich Verdansky y Edouard Le Roy distinguieron la noosfera de la geoesfera, el mundo inanimado, y de la biosfera, el mundo vivo. [ Volver ]