En vez de discutir si es o no posible, vamos a estudiar cómo se podría hacer. Para ello se utilizarán conceptos de Vida Artificial, Algoritmos Genéticos y Sistemas Expertos. En principio, el objetivo es tan ambicioso como conseguir programar un computador para que sea capaz de resolver un problema cualquiera. Una vez acabado el programa, podríamos enfrentarlo a problemas sencillos, comprobando hasta que punto nos hemos acercado al deseado Resolutor General de Problemas. Únicamente se ha de seguir la siguiente norma: estará prohibido introducir conocimiento específico acerca de cómo resolver los problemas particulares con los que después se comprobará su validez. Sin embargo, sí estará permitido introducir conocimiento de nivel superior o metaconocimiento: por ejemplo, cómo obtener conocimiento, o cómo gestionar los recursos que obtienen el conocimiento, etc. ¿Preparados para el reto? A continuación, una serie de sugerencias, que desearía fueran el comienzo de un foro abierto.
En primer lugar, nuestro programa proporcionará una filosofía de trabajo en paralelo, de forma que, aunque el programa sea único, no actúe como una única entidad, sino como varias entidades (o programas) que intentan simultáneamente lograr el objetivo que estamos buscando. Un supervisor seleccionará las entidades que más se acerquen a la meta, generándose nuevas entidades a partir de la combinación de las existentes y por puro azar, como ocurre en los Algoritmos Genéticos. Las entidades también podrán reproducirse, comunicarse, cooperar y competir entre ellas, adquiriendo características propias de los seres vivos. Además, podrán razonar mediante un sistema de reglas, como en los Sistemas Expertos. De esta forma, tendremos unos Agentes que buscarán la combinación de acciones que les lleve a lograr un objetivo, guiándose por la información que reciben de unos sentidos. Un agente podría estar compuesto por un conjunto de agentes de nivel inferior, y así sucesivamente, de forma que un objetivo, representado mediante un agente, pueda descomponerse en subobjetivos, representados por subagentes.
Siendo realistas, si queremos que sea posible aplicar todo esto a nuestros humildes ordenadores personales -y precisamente de eso se trata-, tendremos que tener en cuenta sus limitaciones en cuanto a la entrada/salida. Un problema es un deseo de cambio: tenemos una situación A, una situación B, unos sentidos capaces de captar ambas situaciones, y resolver el problema es hallar la serie de acciones que llevan de A a B, ya que por alguna razón, nos interesa más la situación B que la A [ Nota 3 ]. Para que nuestra máquina pueda resolver un problema, ha de poder recibir de alguna manera los términos en que se define éste: la situación actual (A), y el objetivo al que se desea llegar; algo que permita reconocer cuándo se ha conseguido la meta (situación B). Además, se debe dar la posibilidad de realizar una serie de acciones que actúen sobre los elementos componentes del problema. Por último, nos deberá comunicar la solución a la que ha llegado. ¡Y todo esto hay que programarlo!
Bien, pero ¿cómo se puede producir el aprendizaje? Vamos con un ejemplo. Imaginemos una sala en la que se encuentran 200 personas que jamás han oído hablar de juego del tres-en-raya. Los individuos son reunidos por parejas en mesas que disponen de tableros y se les anima a jugar, ofreciéndoles tres fichas a cada uno. En cada mesa existe un juez que señalará las infracciones cometidas, determinará el ganador -si lo hubiera-, e indicará el final de cada partida.
En un principio se producirá un desconcierto general. Se podrá observar contrincantes intercambiando fichas, colocando varias en una misma casilla o incluso algunos jugando con el tablero del revés. ¡Se puede suponer que los jueces tendrán mucho trabajo!
Después de un tiempo, no sería extraño que algún jugador hubiese colocado por fin tres fichas en línea, después de una serie de movimientos correctos. Si entrevistamos a éste, puede que nos describa cómo descubrió que cada jugador sólo puede colocar sus fichas en alguna de las casillas libres, teniendo que ceder el turno al contrincante cada vez que se hace esto. Sin embargo, es muy posible que aún dude de qué es lo que le hizo ganar la partida.
Este aprendizaje por ensayo y error mediante la ejecución de acciones al azar posee inicialmente una probabilidad muy baja de obtener el resultado deseado. Eso es cierto. Sin embargo, es la única alternativa para quien posee un absoluto desconocimiento acerca del problema al que se enfrenta. Si nos planteamos la construcción de un Resolutor General de Problemas, deberemos tener en cuenta todo tipo de problemas, incluidos aquellos para los que nuestro Resolutor no dispone de ningún conocimiento.
Ahora hagamos que los jugadores estén obligados a enviar mensajes al resto, comunicando sus descubrimientos. De esta forma existirá una superación constante, y tendremos rápidamente a todos los jugadores realizando partidas válidas. Muchas veces se generará conocimiento de dudosa utilidad, pero los jugadores podrán asignar un grado de confianza a cada mensaje en función del número de veces que sea recibido, o en función del éxito producido al utilizarlo en las propias partidas. Siguiendo este método, inevitablemente acabaremos obteniendo 200 expertos jugadores de tres-en-raya.
¿Que hará nuestro programa enfrentado a este juego? El programa es un agente que se enfrenta a una realidad: un entorno, compuesto por el tablero y el contrincante. Este entorno reaccionará de cierta forma ante las acciones que se realicen sobre él. Por ejemplo, después de realizar la acción de colocar una ficha en el tablero, podremos observar el nuevo estado del tablero, que incluye una nueva ficha: ¡la nuestra, evidentemente! Si el nuevo estado que va a adoptar el entorno no depende en absoluto de las acciones que se ejecuten sobre él, tiene poco sentido seguir intentando resolver el problema. Se podría incluso considerar la no-acción como una acción y esperar a que se resolviese por sí mismo.
Sin embargo, supondremos que siempre será posible predecir con una cierta probabilidad el comportamiento del sistema al que nos enfrentamos. Es decir, que existe una relación entre las acciones que realizamos sobre el entorno, y el estado siguiente de este, de forma que es posible asignar una probabilidad a la relación entre un estado inicial, una acción nuestra sobre él, y el estado resultado obtenido con esa acción. Así podremos tener reglas del tipo:
ESTADO + ACCIÓN = NUEVO ESTADO : PROBABILIDAD
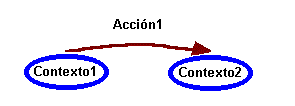
Este formato de reglas de aprendizaje es el propuesto por Drescher, en su libro Made Up Minds, definiéndolo como schema mechanism. La información que recibe el programa acerca del entorno se almacenará en variables. Un estado será un conjunto de valores para esas variables. Por ejemplo, nuestro agente podrá ver el contenido de cada una de las 9 casillas del tres-en-raya, más la decisión del juez, con lo que dispondrá de 10 variables, y las posibles combinaciónes de esos valores formarán el conjunto de estados posibles.
Se trata de predecir el comportamiento del entorno. ¡Pero recordemos que partimos de un completo desconocimiento del problema particular! ¿Qué hacer? En primer lugar, se observa la situación actual -el tablero vacío-, y se comprueba si el objetivo buscado se cumple. Parece ser que todavía nadie nos ha declarado ganadores, por lo que a falta de otra opción mejor, se realizan acciones al azar. Después de una acción se observan sus consecuencias y se produce una asociación causa-efecto que se almacena en forma de regla. Las posteriores acciones estarán condicionadas por el conocimiento almacenado en la memoria, evitándose en lo posible recurrir al azar.
Los agentes no son más que zonas de memoria con datos-instrucciones, a los que se les da "vida" cada vez que se les otorga un pequeño tiempo de ejecución. No nos asombremos; los seres humanos no somos más que zonas de espacio-tiempo con materia. Los agentes realizan un ciclo continuo de observación y acción. Un agente siempre posee un objetivo; una misión que cumplir. Los agentes interpretan la información que reciben de sus sentidos, transformándola en conceptos que definen la situación en la que se encuentran. Así, entre otras cosas, comprueban hasta qué punto se cumple el objetivo que los define. En el caso de no cumplirse éste, deciden según ciertos criterios cuál es la sucesión de acciones que sería necesario ejecutar para lograr la meta y a continuación ejecutan dichas acciones.
En el caso del tres en raya, el objetivo es ganar el juego. Los sentidos nos informan en cada momento del estado del tablero, que se almacenará en la memoria. Las acciones son no sólo las que actúan directamente sobre el problema que se está resolviendo, como colocar una ficha, sino también aquellas que producen razonamiento, aquellas que consisten en manejar de alguna forma el conocimiento almacenado en la memoria, y que posteriormente determinarán la secuencia de acciones a realizar sobre el entorno.
Si se realiza una acción y se pasa a un estado desconocido, se almacenará información que represente ese nuevo estado y se creará una regla que represente las condiciones necesarias para pasar a ese nuevo estado.
El problema consiste cómo identificar qué acción ha sido la responsable de una transición. Por ejemplo, colocar una ficha en un determinado lugar puede ser la causa inmediata de ganar la partida, pero tiene poca utilidad suponer que únicamente esa acción es la responsable de vencer en el juego. Es más apropiado decir que la causa es la sucesión completa de acciones desde el comienzo de la partida.
Para poder utilizar este tipo de reglas, las acciones se podrán organizar en una estructura jerárquica. Así, una sucesión de acciones interesante formará una acción de nivel superior, y esta acción podrá formar parte de una regla.
Sin embargo, normalmente esto no explica la mayoría de las situaciones. Una partida no se gana por realizar una determinada serie de acciones, sino más bien por una estrategia, por un conocimiento del juego en general, por un conocimiento de experto obtenido a través de múltiples experiencias.
A este nivel de análisis, la causa de haber ganado es el haber realizado una serie de acciones -tomar una decisión es realizar una acción-, que aunque no actúan sobre el entorno o problema a resolver, manejan símbolos referentes a él y manipulan o indican cómo manipular la información adquirida, determinando cuál será la sucesión de acciones a realizar sobre el juego. Es decir, no sólo se trabaja con acciones que actúan directamente sobre el problema, sino también con acciones de nivel superior que actúan sobre los procesos que determinan las acciones.
Ejemplos de acciones que no actúan directamente sobre el problema son: - leer el estado del tablero
- buscar en la memoria un estado similar al actual
- buscar una regla en cuya parte derecha se encuentre un determinado estado
Pensando en el programa como en un conjunto de agentes o entidades, una acción puede consistir en: - crear nuevas entidades
- eliminarlas
- modificarlas
Recordemos que las entidades pueden combinarse y crear nuevas entidades con características de sus progenitores (reproducción sexual), pudiendo producirse modificaciones al azar (mutaciones genéticas). También es posible simular una selección darwiniana haciendo desaparecer aquellas que no consiguen sus objetivos o asignándoles un tiempo de ejecución menor.
Aunque en cada instante sólo se pueda ejecutar una acción básica, las acciones de nivel superior se pueden solapar en el tiempo. La toma de una decisión cuya influencia se manifiesta en el desarrollo de otras acciones puede entenderse también como una acción. Por ejemplo, el hecho de decidir utilizar, bajo ciertas condiciones, únicamente un subconjunto del conjunto total de reglas posibles, puede considerarse una acción (de nivel superior). Esta acción se solapará con las acciones básicas que se ejecuten en cada momento. Este ejemplo además ilustra como permitir una cierta jerarquía dentro de las reglas, ya que es posible incluir esta acción, que hace referencia a las reglas, dentro de otra regla.
El número de variables que forman un estado normalmente será muy grande, y muchas veces ocurrirá que varios estados distintos se comportan como uno sólo. Esta última situación se observa en el caso del tres-en-raya, por ejemplo, en la simetría que posee el tablero. Por estas razones puede ser interesante representar algunas combinaciónes de valores de variables como un único valor para una variable de nivel superior.
Así, dispondremos de un mecanismo que nos permitirá algo parecido a crear conceptos. Por ejemplo, se podría crear el concepto de "dos fichas en línea", que será una nueva variable, que adoptará el valor verdadero en el caso de que se produzca esta situación. Aquí es posible aplicar la Lógica Difusa. Existen conceptos de naturaleza continua, que se definen mediante la referencia a una propiedad y el grado en que se manifiesta dicha propiedad. Por ejemplo, nosotros podemos decir que el cielo es azul. Sin embargo, no existe una frontera numérica que marque la diferencia entre un cielo azul y un cielo blanco en función del número de puntos de luz de cada color. Ambos conceptos pueden ser ciertos simultáneamente en cierta medida. Así, podríamos expresar: el cielo posee un tono azulado en un 70%. Por otra parte no siempre se dará un grado de confianza "total" a la información manejada. Es posible que un concepto se cumpla en un cierto grado y que a esta información se le asigne una cierta confianza, y de esta forma, podríamos decir: el cielo posee un tono azulado en un 70% y esta información posee una probabilidad del 90% de ser cierta. Estos aspectos deberán ser incluidos en cada variable.
¿Cómo reconocer que conceptos son importantes? Se ha de intentar que no sea necesario que cada agente deba recordar todos los estados por los que ha pasado. Cuando un agente llegue a su límite de almacenamiento, deberá seleccionar algunos recuerdos para que sean borrados. Para ello, intentaremos relacionar los estados con el objetivo, de manera que se tengan más en cuenta aquellos que más influyen en él, ya sea favoreciendo o perjudicando su consecución.
La creación de nuevas variables de nivel superior también hace que las necesidades de espacio a la hora de almacenar una regla sean menores. Con un número suficiente de reglas describiendo el comportamiento del entorno, y conociendo el estado actual y el estado al que se desea llegar, se puede buscar la sucesión de acciones que nos llevan de un estado a otro, hasta la meta.
La creación de variables superiores no ha de estar limitada a un solo instante de tiempo, a una sola lectura del entorno. En realidad, el tiempo se puede considerar como una variable más, y crear así conceptos que describan un comportamiento complejo que posea continuidad.
Volviendo al tres-en-raya, una vez que nuestro agente principal es capaz de jugar sin infringir las reglas, pero aún no sabe cómo ganar, puede crear uno (o varios) agentes idénticos a él (o ligeramente modificados) y representar partidas en una "simulación interna", durante cierto tiempo, antes de decidirse a mover una ficha en la "simulación externa" contra la que le hemos enfrentado. En la "simulación interna" es posible representar la misma situación que se produce en la "simulación externa", o cualquier otra situación que se considere interesante.
Por ejemplo, se pueden generar 200 agentes, que jugarán por parejas. Al principio, cada agente jugará basándose únicamente en una regla que ha sido generada al azar, del tipo "Si observo tal situación, realizo tal acción", y que el agente aplica cuando es posible. En caso de no poder ser aplicada ninguna regla, el agente realiza acciones completamente al azar.
Después de las partidas, se pueden seleccionar los agentes ganadores y crear nuevos agentes que posean esta vez dos de las reglas que resultaron útiles en la partida anterior, añadiendo además nuevas reglas al azar. El ciclo se puede repetir indefinidamente. Con un proceso de este tipo, los agentes poseerán cada vez mayor conocimiento, hasta lograr una entidad con un conjunto de reglas óptimo para el problema descrito.
Podría existir uno (o varios) agentes de nivel superior con el objetivo de realizar la selección de otros agentes. Esta entidad también trabajará con un conjunto de acciones posibles, objetivos, etc. Y siempre que exista un agente, podrá existir otro agente de nivel superior que controle al anterior, modificando los parámetros que son constantes para el agente inferior.
Para medir el éxito de nuestro programa, es más importante observar la tendencia de éste, que los resultados concretos. Podemos crear una gráfica que relacione la utilidad o la calidad del conocimiento adquirido por las entidades en función del tiempo que ha sido necesario para que esto suceda. También podría hacerse lo mismo en relación con la cantidad de memoria empleada, en vez del tiempo.
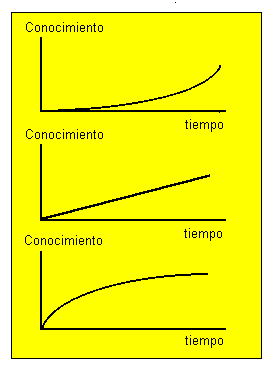
La primera de las gráficas corresponde al comportamiento ideal, en el que el conocimiento aumenta exponencialmente, con lo que se puede esperar resolver un problema cualquiera, y además en un breve tiempo. En la segunda, el conocimiento aumenta de forma constante. Un sistema así siempre sería capaz de obtener el conocimiento buscado en un tiempo finito.
Sin embargo, la tercera corresponde con un sistema que a pesar de poseer un gran incremento del conocimiento en el inicio, éste se estabiliza en un cierto valor, con lo que no se cumplirá el objetivo de disponer de un sistema capaz de resolver un problema cualquiera, a no ser que el valor de máximo conocimiento al que se tiende sea tan grande que se pueda considerar infinito.
 | Drescher, Gary L. 1991. Made Up Minds. MIT Press.
|
| Hofstadter, Douglas R. 1987. Gödel, Escher, Bach. Un eterno y gracil bucle. Tusquets Editores & CONACYT.
|
| Klein, Stephen B. 1994. Aprendizaje. Principios y aplicaciones. McGraw Hill.
|
| Matute, Helena. 1993. "Aprendizaje y representación de conceptos" en Aprendizaje y memoria humana: aspectos básicos y evolutivos. J.I. Navarro (Ed). McGraw Hill.
|
| Alberdi, Eugenio; Matute, Helena; Rementería, Santiago. 1992. "Aprendizaje a partir de ejemplos y asignación de pesos" en Nuevas tendencias en inteligencia artificial. Moral, A. y Llaguno, M. (Ed.) Universidad de Deusto.
|
[1] Herrán Gascón, M. de la (1996). Agentes Autodidactas ¿Futuro o Realidad?. Revista BASE (nº 30) de la Asociación de Licenciados en Informática (ALI). [ Volver ]
[2] Director de la publicación REDcientífica.com [ Volver ]
[3] Existe otra forma de resolver el problema, sin ir de A a B, que es dejar de desear ir de A a B. [ Volver ]